可观察性
可观察性有助于跟踪系统的内部工作原理,而无需更改系统。这使得调试和评估整体性能变得更加容易。
txtai 集成了 MLflow 及其跟踪模块,以便深入了解 txtai 中的每个组件。
示例
以下展示了如何在 txtai 进程中引入可观察性的几个示例。
初始化
请先运行以下章节以初始化跟踪。
# Install MLflow plugin for txtai
pip install mlflow-txtai
# Start a local MLflow service
mlflow server --host 127.0.0.1 --port 8000
import mlflow
mlflow.set_tracking_uri(uri="https://:8000")
mlflow.set_experiment("txtai")
# Enable txtai automatic tracing
mlflow.txtai.autolog()
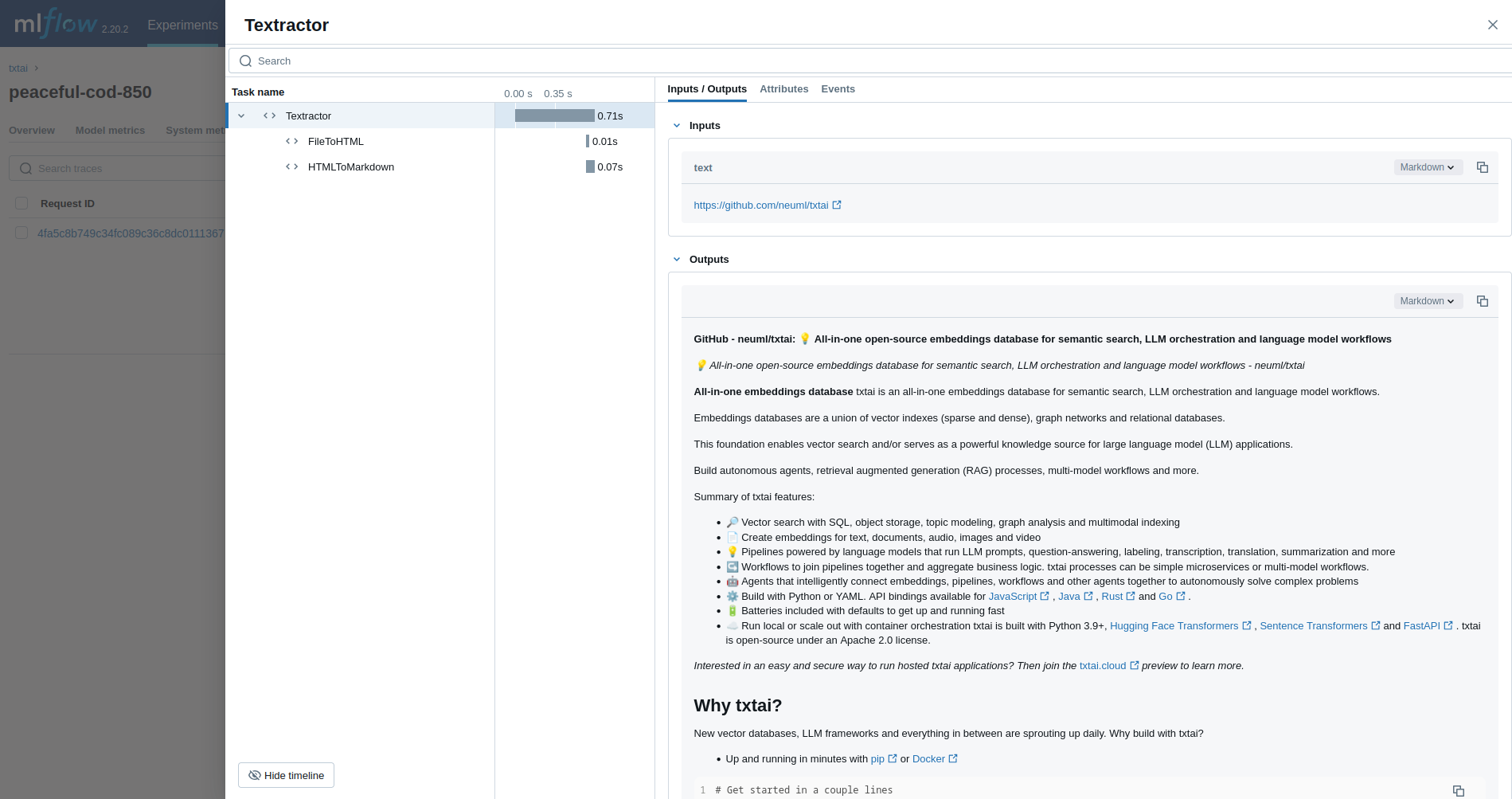
Textractor
第一个示例跟踪 Textractor 管道。
from txtai.pipeline import Textractor
with mlflow.start_run():
textractor = Textractor()
textractor("https://github.com/neuml/txtai")
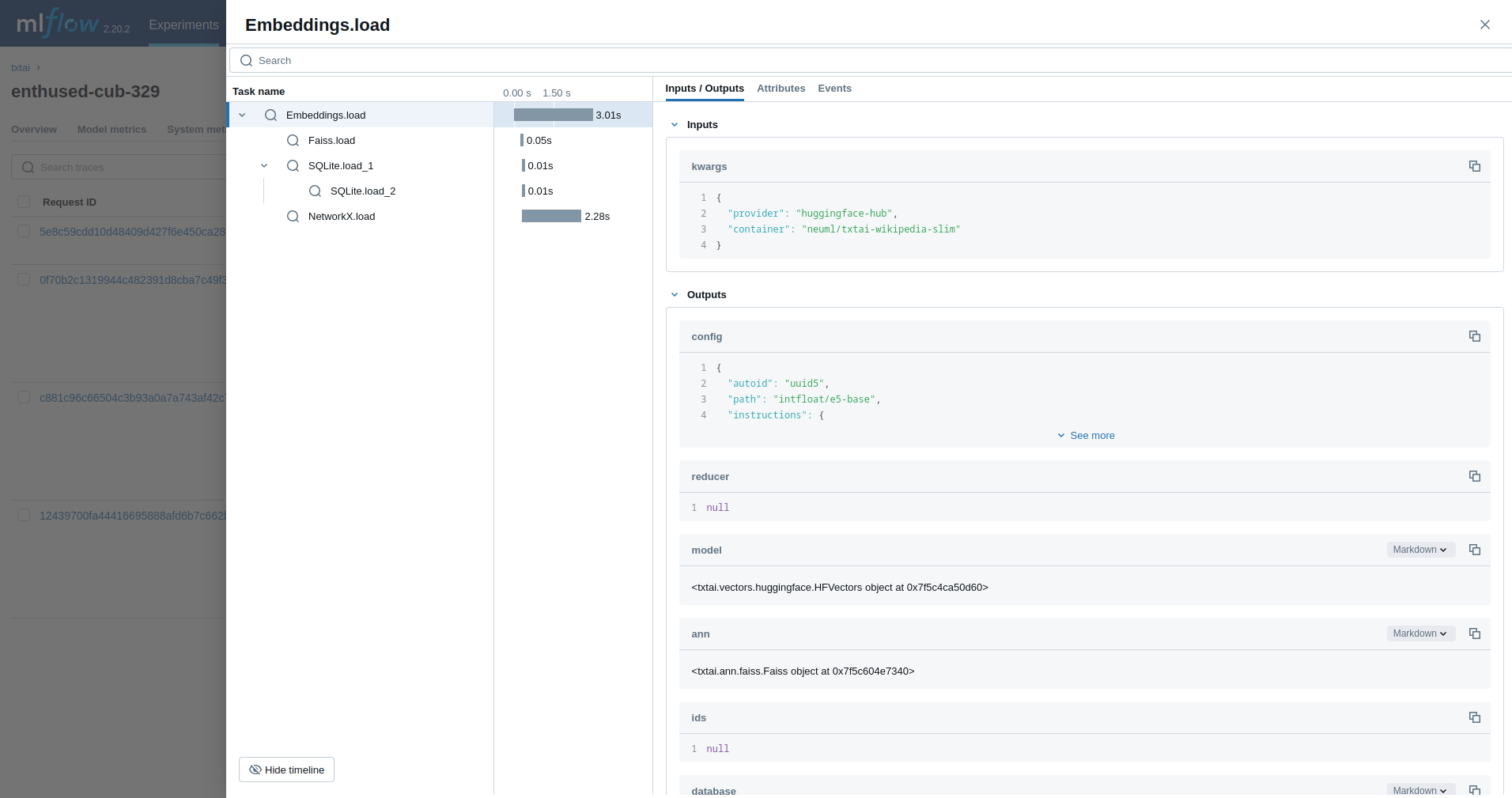
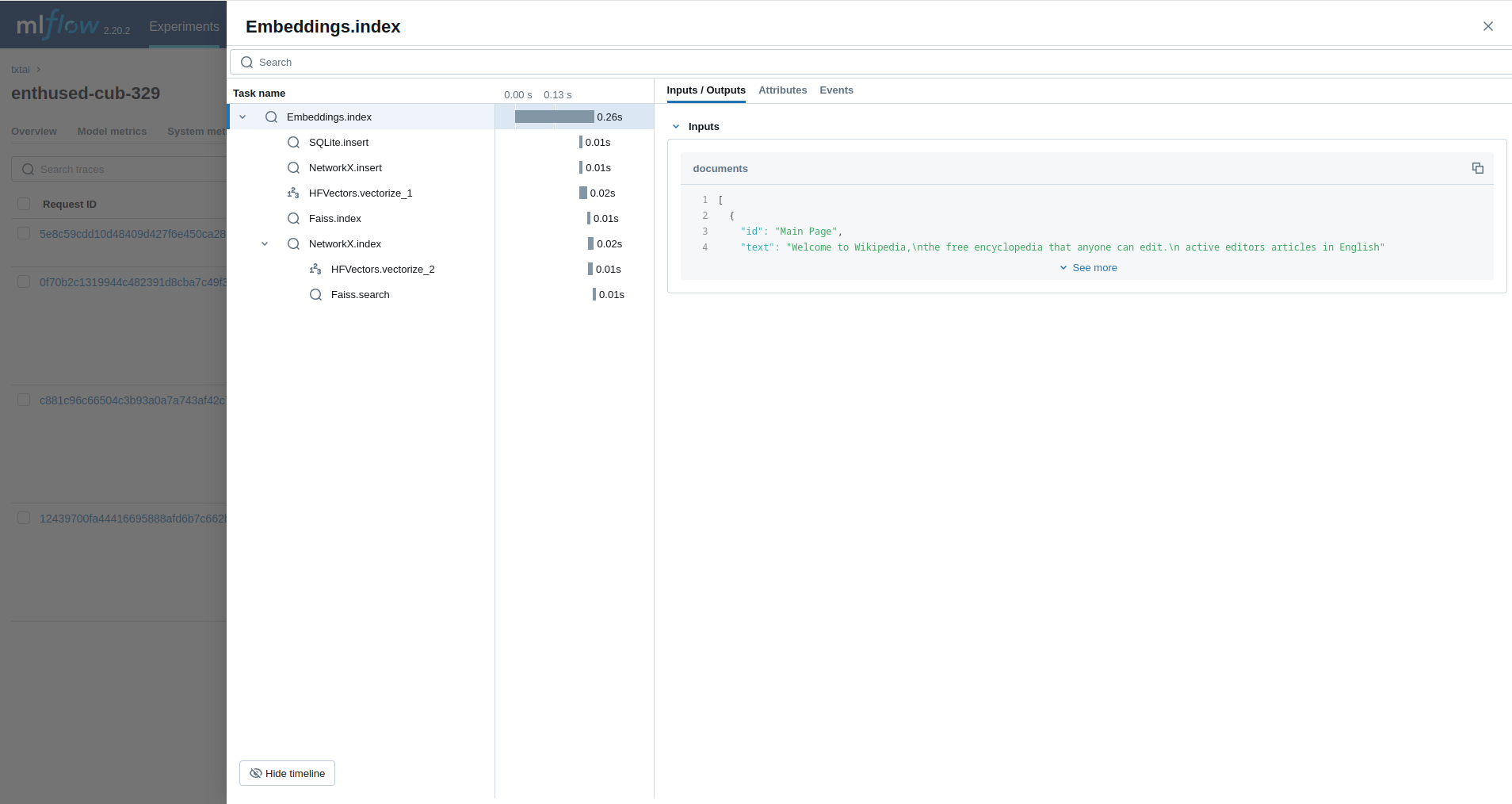
嵌入
接下来,我们将跟踪一个嵌入查询。
from txtai import Embeddings
with mlflow.start_run():
wiki = Embeddings()
wiki.load(provider="huggingface-hub", container="neuml/txtai-wikipedia-slim")
embeddings = Embeddings(content=True, graph=True)
embeddings.index(wiki.search("SELECT id, text FROM txtai LIMIT 25"))
embeddings.search("MATCH (A)-[]->(B) RETURN A")
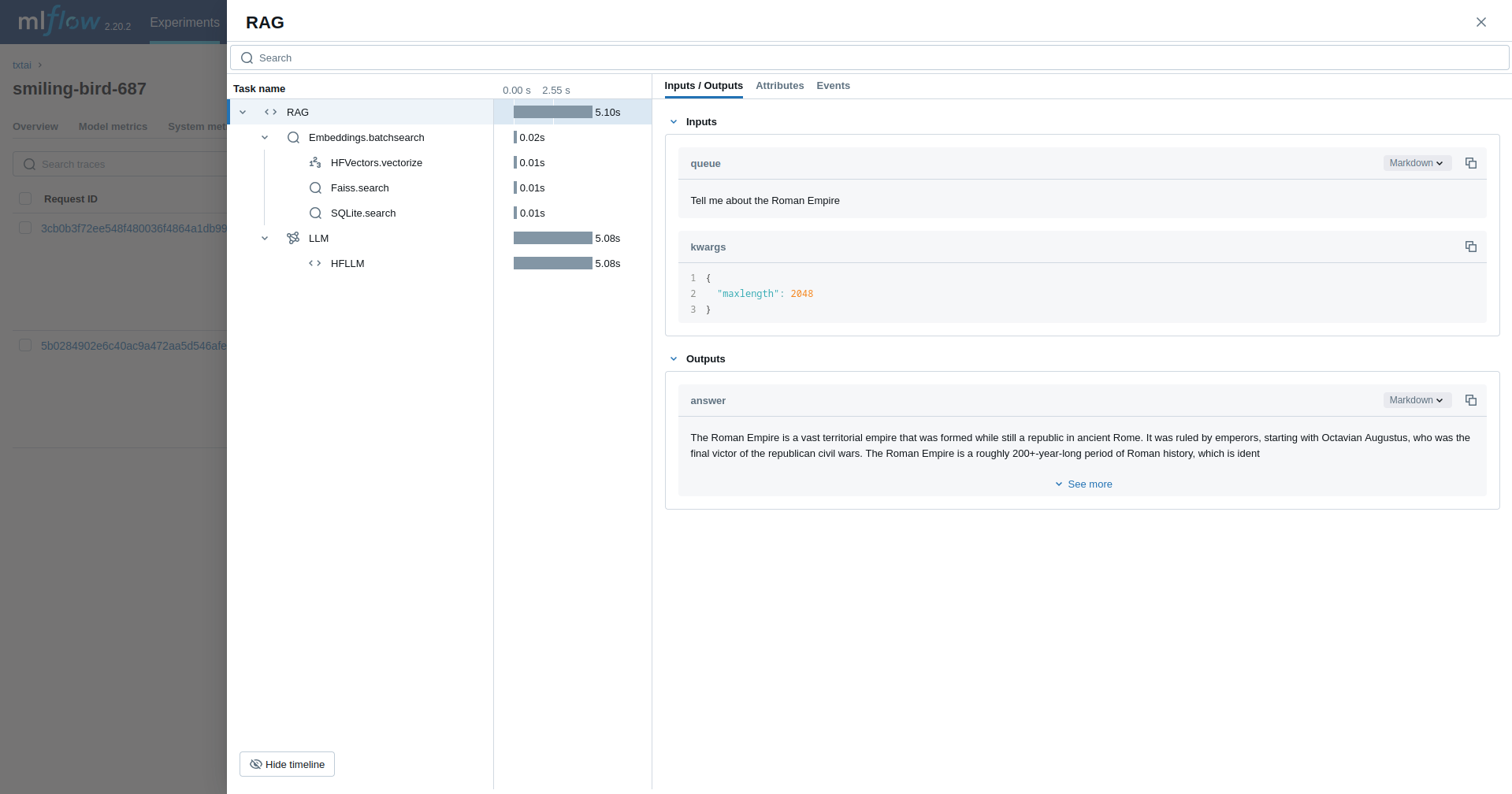
检索增强生成 (RAG)
下一个示例跟踪一个RAG 管道。
from txtai import Embeddings, RAG
with mlflow.start_run():
wiki = Embeddings()
wiki.load(provider="huggingface-hub", container="neuml/txtai-wikipedia-slim")
# Define prompt template
template = """
Answer the following question using only the context below. Only include information
specifically discussed.
question: {question}
context: {context} """
# Create RAG pipeline
rag = RAG(
wiki,
"hugging-quants/Meta-Llama-3.1-8B-Instruct-AWQ-INT4",
system="You are a friendly assistant. You answer questions from users.",
template=template,
context=10
)
rag("Tell me about the Roman Empire", maxlength=2048)
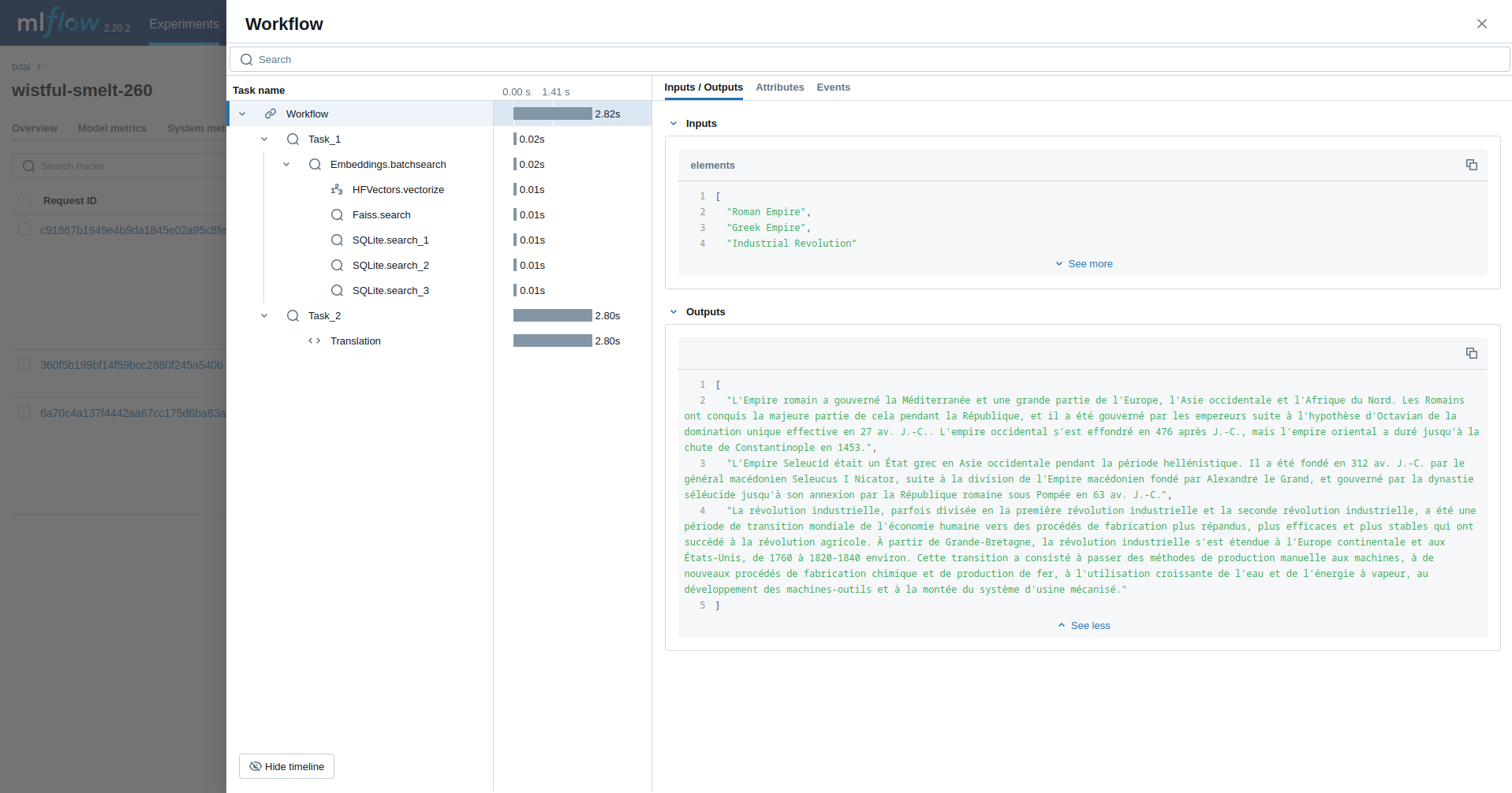
工作流
这个示例运行一个工作流。此工作流运行一个嵌入查询,然后将每个结果翻译成法语。
from txtai import Embeddings, Workflow
from txtai.pipeline import Translation
from txtai.workflow import Task
with mlflow.start_run():
wiki = Embeddings()
wiki.load(provider="huggingface-hub", container="neuml/txtai-wikipedia-slim")
# Translation instance
translate = Translation()
workflow = Workflow([
Task(lambda x: [y[0]["text"] for y in wiki.batchsearch(x, 1)]),
Task(lambda x: translate(x, "fr"))
])
print(list(workflow(["Roman Empire", "Greek Empire", "Industrial Revolution"])))
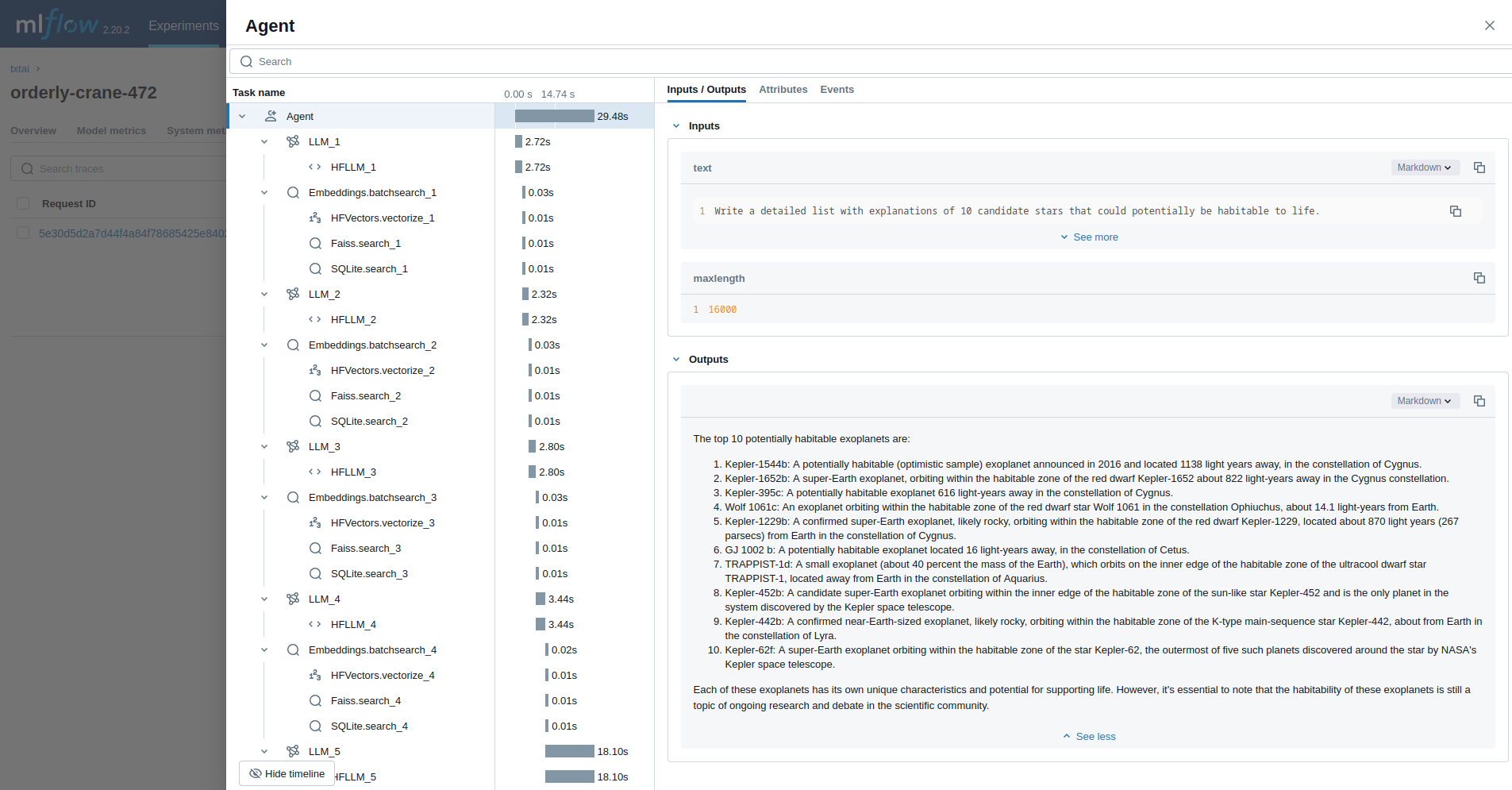
代理
最后一个示例运行一个旨在研究天文学问题的 txtai 代理。
from txtai import Agent, Embeddings
def search(query):
"""
Searches a database of astronomy data.
Make sure to call this tool only with a string input, never use JSON.
Args:
query: concepts to search for using similarity search
Returns:
list of search results with for each match
"""
return embeddings.search(
"SELECT id, text, distance FROM txtai WHERE similar(:query)",
10, parameters={"query": query}
)
embeddings = Embeddings()
embeddings.load(provider="huggingface-hub", container="neuml/txtai-astronomy")
agent = Agent(
tools=[search],
llm="hugging-quants/Meta-Llama-3.1-8B-Instruct-AWQ-INT4",
max_iterations=10,
)
researcher = """
{command}
Do the following.
- Search for results related to the topic.
- Analyze the results
- Continue querying until conclusive answers are found
- Write a Markdown report
"""
with mlflow.start_run():
agent(researcher.format(command="""
Write a detailed list with explanations of 10 candidate stars that could potentially be habitable to life.
"""), maxlength=16000)
阅读更多
查看 mlflow-txtai 项目以查看更多示例。